Fine-Tuning is important to get the optimal outcomes from LLMs (large Language Models). Fine-tuning is more like training your AI models to make the outcomes more refined. Supervised Fine Tuning can help train your LLM models using labeled data. This model bridges the gap between the model’s general language understanding and targeted understanding.
To apply LLMs in practice, fine tuning is crucial as it directs the models to work in a certain way. Plus, supervised fine-tuning optimizes the AI models to perform your specific tasks. Well, there’s more you can explore with this fine-tuning method. Let this blog help you understand supervised fine-tuning in a comprehensive manner.
Get into it!
What is supervised fine tuning?
Recently, in AI research, the use of supervised training has increased. This brings the highest-quality LLM outcomes in standard language modeling objectives. However, the best part of this model is its simplicity. Because of this, this method is widely famous among the open-source LLM research community.
Now get into the concept.
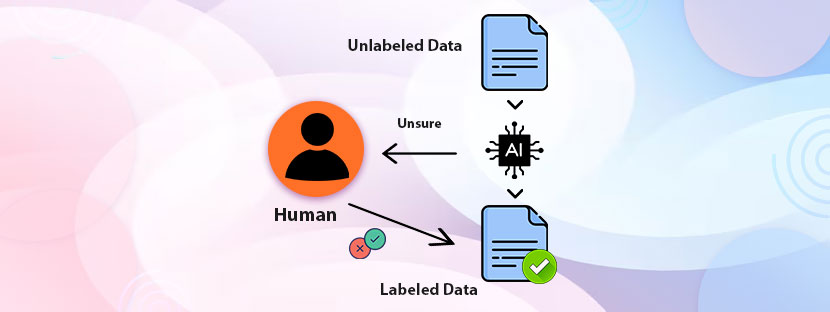
Supervised Fine Tuning (SFT) is a process that helps you make a pre-trained language model to perform specific tasks better. It needs labeled data to teach your model what to do. This helps your model to perform specific tasks.
Pre-trained models are good at performing basic tasks, per se, general tasks. However, it often lags when it comes to getting the specific tasks. With the help of fine-tuning, pre-trained LLM models can perform specific functions, but more efficiently. Basically, SFT is done once pre-training of the model is over.
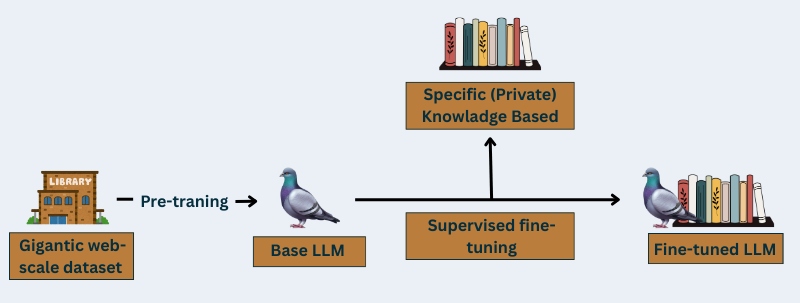
How supervised fine tuning works
From a basic language model to becoming a perfect LLM, fine-tuning makes the journey smooth for AI models with the help of SFT. You can provide comprehensive training to your LLM model with the following THREE-Steps;
Pretraining
First, we need to create the baseline foundation with the existing popular LLM architectures. It’s the most expensive step of this entire pipeline as it requires a large amount of data accumulated from all corners. To prepare the entire pre-training database, you need expensive hardware and several days of data training. Although the training models cover all knowledge areas they can still be specialized further into anything more specific.
Data Labeling
Trained data is the foundation of a supervised fine-tuning model. Data labeling is becoming the core element of success in the development of AI technology. In 2024, the AI market stood at $184 billion, and it’s more likely to increase into double in the coming years. Thus, the demand for data labeling will be increasing over time.
However, in SFT, ML engineers annotate high-quality datasets to train the LLM. They not only annotate but also collect, process, and then label all data according to the model’s unique needs.
Fine-Tuning
Now, when you have all the training data and the pre-trained model, you can start with supervised learning. You need to integrate the trained datasets into the existing system. You can tweak a bit if needed to start with your LLM fine-tuning.
Techniques of supervised fine tuning
LLM is one of the deep learning models that has multiple layers. Each layer handles different aspects of tasks and makes the model enriched. But remember one thing, not each layer demands to be updated during the fine-tuning process. All the techniques of fine-tuning apply differently for different use cases and demands on resource availability.

These are some of the popular SFT techniques,
Full Fine-Tuning
This model involved updating all the existing parameters of the LLM starting from scratch. That is the reason why this technique is costly and needs frequent parameter updates. Interestingly, this model learns data features all its layers plus it understands subtitles for domains. This technique suits when you have time as well as resources intact.
Parameter-Efficient Fine-Tuning
It’s an alternative of the full fine-tuning model. This model adds extra task-specific laters to downstream tasks. It keeps other layers frozen while working with the existing layer. However, developers can have an option to unfreeze some laters while working with the model. Compared to full fine tuning, this model can do work with less computational cost.
Instruction Fine-Tuning
Instead of targeting the knowledge base, this model works on improving the model’s instruction-following capabilities. It focuses on the model’s instruction-following abilities.
Key Advantages of Supervised Fine-Tuning
SFT is a comprehensive and collaborative process; it includes data collection as well as data labeling. However, due to additional features and complexities present in the model, this can provide you with several benefits.
Improved Performance
With the incorporation of supervised fine-tuning, your LLM can perform specific tasks instead of handling general tasks. It can go above and beyond delivering better outcomes from your language models. The best part is the model can deliver accurate outcomes once the SFT is done perfectly. It can generate responses promptly and sound relevant instead of answering general queries.
Versatility and Flexibility
Fine-tuning the AI models allows developers to tweak output responses. Therefore, with SFT, you can instruct your AI model to respond according to the domain’s requirements. Therefore, the model can respond differently when you add restrictions. It will follow all the restrictions and provide you with different moderated responses. Hence, we can say the model is flexible and versatile.
Cost-Efficiency
Fine-tuning can be done on a small dataset with software backup. Plus, it can be delivered within a few hours. Unlike the big GPUs, fine-tuning costs less and can be done with limited datasets. One thing that is important here is the accurate data collection and the right amount of annotated datasets.
Data Efficiency
As we said before, supervised fine-tuning perfectly suits situations where data is limited. It can start from scratch and gradually cover the knowledge base. The LLM can pull data like sentence structuring and others from pre-existing knowledge. Therefore, this model does not require to train the model from the scratch. It can only fine tune the model with annotated data, that too with a limited amount.