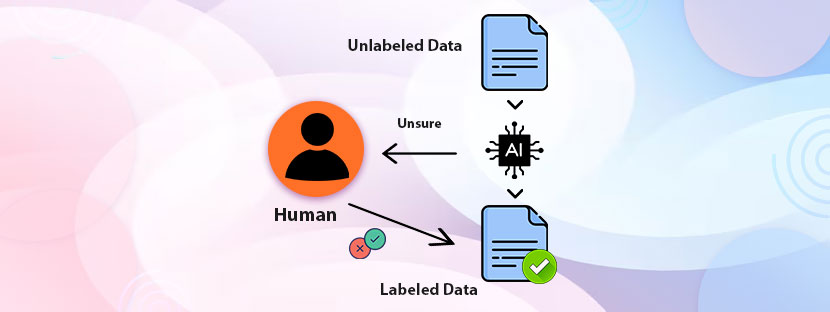
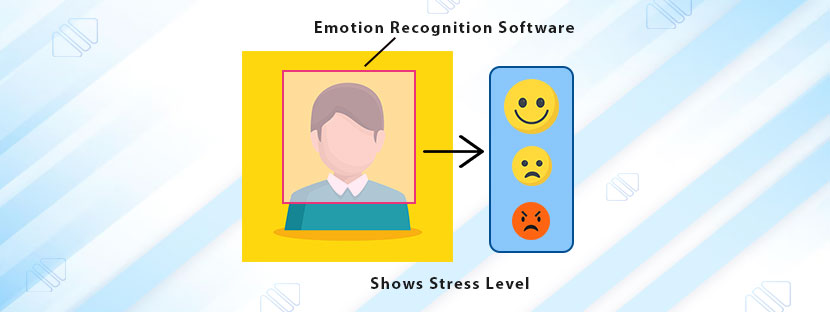
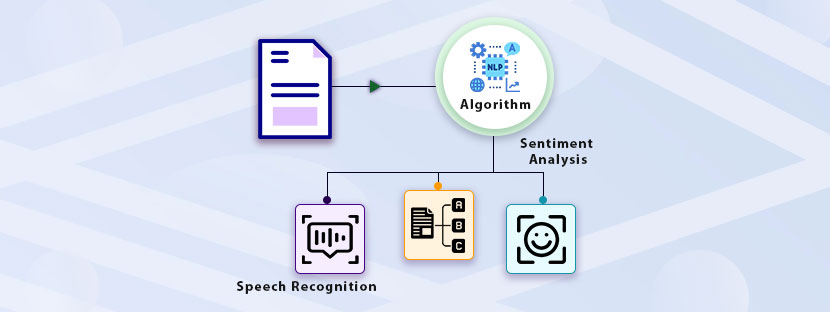
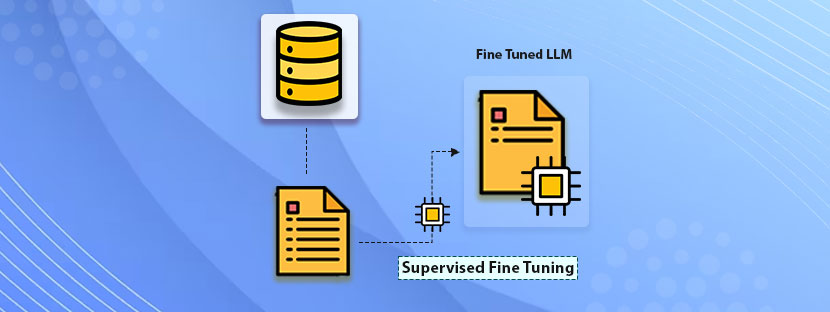
Object tracking is the key method behind various modern Artificial Intelligence (AI) applications. Self-driving cars, automated surveillance, Augmented Reality applications, etc, are examples of implementations of object tracking in the machine learning process.
Often, object tracking and object detection, both as concepts, are taken interchangeably. Well, both these methods help detect and localize objects within a video frame, but there are many differences between them. Let this blog help you understand the object tracking method accurately. We will highlight the differences between object tracking and detection and showcase the importance of data labeling here.
Let’s get started!
Object Tracking in Computer Vision
Object tracking is a method to monitor an object’s position across several frames in a video. It helps machines to identify the chosen objects in a video automatically. Basically, object tracking is a training or data annotation technique that builds computer vision models.
In deep learning, accurate labeling of object positions in video frames helps the ML algorithms understand the objects’ directions. Hence, it builds computer vision technology where the machine can detect objects and make decisions based on that.
In simple words, object tracking identifies objects on a video frame and labels them with high precision. It puts a square as an indication around the moving objects to show the user where the object is located in the video frame.
Object Detection vs Object Tracking
While object tracking focuses on following an object over time in a frame sequence, on the other hand, object detection focuses on localizing the object within a video frame. Both terms sound similar, but they perform tasks differently. Let’s assess the differences present between them with the help of a table here.
Methods for Object Tracking
In machine learning, two primary ways are there that help detect objects in video frames. These are;
- Single Object Tracking
- Multiple Object Tracking
As the name suggests, single object tracking, or SOT is ideal when it comes to tracking a single object in a video frame. For example, tracking a player in a game. On the other hand, multiple object tracking or MOT helps in tracking complex video frames where multiple objects overlap each other. For example, a real-time traffic monitoring application that tracks multiple objects at the same time.
Types of Object Tracking
Input data matters when it comes to object tracking. The impact of input data directly gets reflected in the output. There are several categories of input data available, including images, videos (real-time videos and pre-recorded videos), to help your computer algorithm create computer vision applications.
Here are the types of object tracking you can have;
Video Tracking
Moving objects are getting tracked with the application of video tracking. You can track objects in real-time videos as well as pre-recorded videos also with the help of video tracking. This method only tracks the objects that enter, stay, and leave the video frame. It constantly tracks the objects within the video frames.
Image Tracking
Object tracking can help identify objects that appear in different images. You can find similar-looking objects that appear in different images with the help of this method. Images can be any type, be it in black and white, asymmetrical, or patterned, image tracking detects the objects within any image with the highest range of precision.
Visual Tracking
Visual tracking is a process to predict what object will come next without the availability of a complete video. This type of object tracking method works better with broken video footage. However, machines can predict the next footage only if the video captures a large range of everyday scenarios.
Accurate Labeling for Object Tracking
Currently, the global market size for computer vision development models is expected to stand at USD 29.8 billion by the end of 2025. The market for computer vision technology and its practical applications will increase over the years. To develop computer vision, the first and foremost thing you need is labeled datasets.
Annotating data accurately is the only thing that can produce strong LLMs for computer vision technology. Object tracking as a task can be performed perfectly only if you accurately label your data and train your machine learning models with that.
The chances of occlusion are pretty high in real-time footage, so a high standard of data annotation is the prime requirement at this point. However, with the help of a professional data annotation company, you can prepare your desired training data that you need for your computer vision projects.
Here are the ways you can label your objects in a video frame using labels;
Manual Labeling
Get accurate labels attached to your objects in a video frame with the help of manual labeling. It’s a labor-intensive process, and it needs constant monitoring and a comprehensive understanding of the labeling technicalities. However, the outcome of manual labeling is super accurate and highly useful for precise ML model development.
Automated Labeling
Quite faster than manual labeling, this object labeling process involves the use of high-powered AI technicalities. This can label your dataset faster, along with maintaining the accuracy level. This process can suit you best when you need labeled data for object detection model development in less time.
Hybrid (Automated + Manual)
Going through a mixed approach is best when it comes to getting the right types of annotated data. The hybrid approach is a combination of labeling objects with the help of AI tools, but under strict manual monitoring. It means you can get the delivery of highly accurate annotated data at the right time.