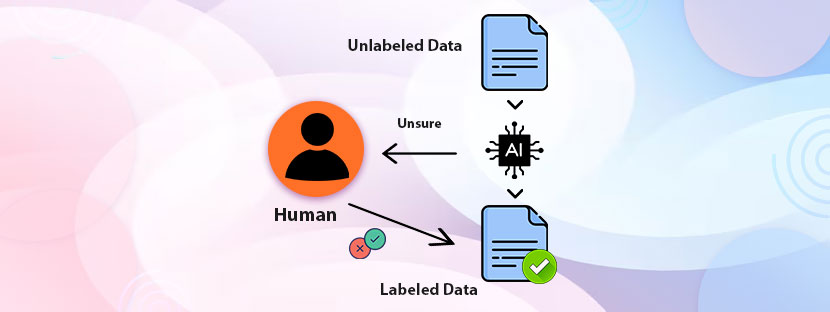
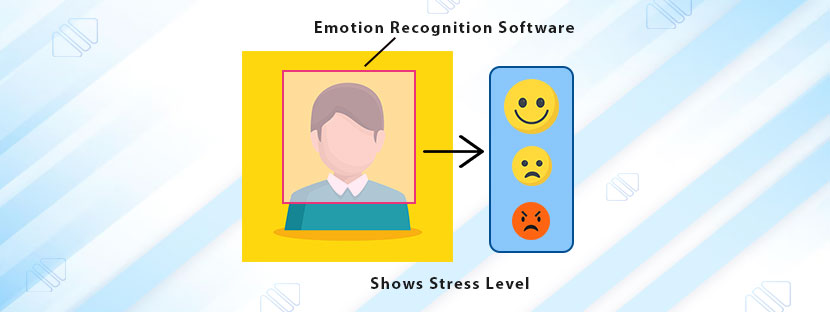
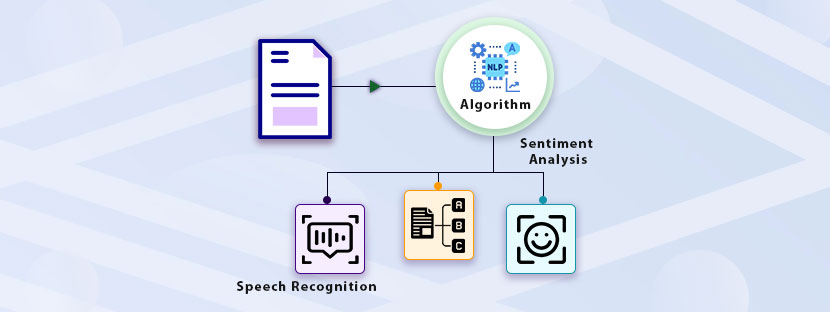
Text annotation is a part of natural language processing (NLP) in which textual data is labeled and its various components are highlighted. Annotating text is important for developing language-based Artificial intelligence (AI) models. Providing training to AI models with text data includes many tasks. It includes a separate learning process to manage annotation work perfectly.
Annotating text for NLP applications includes a lot of tasks; named entity recognition, sentiment analysis, part-of-speech tagging, and much more. The market share of NLP is sharply rising at present. A recorded turnover of $12 billion was detected in 2020 here. Based on some estimates, the market will grow at a rate of 25% in the coming years.
However, annotating text and textual components through NLP is quite a tough process and that’s where two-thirds of NLP systems failed. At present, generative AI is taking place all over the digital grounds, be it in search results, content generation, or everywhere. Therefore, proper annotation of text data is important to get you the best language-based AI model. This blog covers everything about text annotation and the way it works in this process.
Important Considerations While Annotating Text for NLP
Among other techniques of Natural Language Processing, text annotation is quite critical. It heavily relies on accurately labeled datasets. Most data annotators make mistakes while labeling text data. To maintain the speed and consistency of annotation tasks, they maintain the following considerations;
Production Speed
The rate of textual data generation in our fast-paced digital world is rapidly increasing. All thanks to social media social media platforms generate enormous amounts of data daily. Annotators are under pressure to work quickly, which can sometimes compromise the accuracy and depth of annotation. This need for speed can also lead to burnout among annotators.
Data Security
Annotators often work with sensitive data, which might include personal information. Ensuring the security and privacy of this data is paramount. Data breaches can have serious consequences, not just for the individuals whose data is compromised, but also for the organizations handling the data. Annotators and their employers must adhere to strict data protection protocols, adding another layer of complexity to their work.
Ambiguity in Language
Natural language is inherently ambiguous and context-dependent. Capturing the correct meaning, especially in cases of idiomatic expressions, sarcasm, or context-specific usage, can be difficult. This ambiguity can lead to challenges in ensuring that the annotations accurately reflect the intended meaning.
Resource Intensiveness
Text annotation is often a time-consuming and labor-intensive process. It requires a significant amount of human effort, which can be costly and inefficient, especially for large datasets.

Subjectivity in Interpretation
Different annotators may interpret the same text differently. Achieving consensus or a standardized interpretation can be challenging.
Language and Cultural Diversity
Dealing with multiple languages and cultural contexts increases the complexity of annotation. It’s challenging to ensure that annotators understand the nuances of different languages and cultural references.
Domain-Specific Knowledge
Certain NLP applications require domain-specific knowledge (such as legal, medical, or technical fields). Finding annotators with the right expertise can be difficult and expensive.
Scalability
As the amount of data increases, scaling the annotation process efficiently while maintaining quality is a major challenge. Automated tools can help, but they often require human validation to ensure accuracy.
Consistency
Maintaining consistency in annotation across different annotators and over time is a significant challenge. Different interpretations of guidelines, varying levels of understanding, and even changes in annotators’ perceptions over time can lead to inconsistent labeling. Inconsistent annotations can confuse the NLP models, leading to poor performance.
Annotation Guidelines and Standards
Developing clear, comprehensive annotation guidelines is crucial for consistency. These guidelines must be regularly updated and annotators adequately trained, which adds to the complexity and costs.
Adaptation to Evolving Language
Language is dynamic and constantly evolving. Keeping the annotation process and guidelines up to date with new slang, terminologies, and language usage patterns is an ongoing challenge.
Human Bias
Annotators, being human, bring their own perspectives and biases to the task. This can affect how the text is interpreted and labeled. For example, in sentiment analysis, what one annotator might label as a negative sentiment, another might view as neutral. This subjectivity can lead to inconsistencies in the dataset, which in turn can skew the NLP model’s learning and outputs.
Popular Techniques to Annotate Text

In NLP, the method you follow to annotate text plays the most vital role in shaping the effectiveness of your AI program. Hence, selecting the right technique is vital in this process. Plus, understanding the different text annotation techniques is a must here. If we generalize all available annotation techniques, we can get mainly three types of techniques, which are;
I. Manual Annotation
Manual annotation involves human annotators who label texts by following text annotation guidelines. Manual annotation techniques have the highest accuracy rate than other annotation methods. Plus, it provides a contextual understanding of each specific project and provides you with more flexibility.
Manual annotation techniques are ideal for specialized sectors like healthcare, academic research, etc because they need more accuracy. And, Manual annotation is all about reaching new heights of accuracy. Well, on the downside, the process takes time and overwhelmingly focuses on labor. Added to that, the process can include issues like bias and human-led errors.
II. Automated Annotation
Automated annotation basically means using any application to label texts without any human interference. The underlying algorithm within the machine would annotate text data automatically. Many applications are now available in the market that can automate labeling tasks.
Automation is required the most where the working sphere is large. For example, social media research or annotation projects need quickly annotated data to operate. That’s when the need for an automated system is realized. More than that, an automated system is necessary in big data projects for faster data processing. However, when it comes to handling complex situations, then automated system might work a little less.
III. Semi-Automated Annotation
As the name suggests, semi-automated techniques are a combination of automated and manual processes. In these methods, machines perform the initial annotation part, and human annotators review and refine the annotation task. These techniques work wonders in large-scale projects where specifications play an important role.
Semi-automated annotation techniques strike the perfect balance between speed and accuracy. Using these techniques can efficiently decrease human workload and make the system more adaptable. Talking about the downside, having a semi-automated process requires both; technological as well as human expertise. Plus, the complexity of the management can harm the process so you need to take additional care here.
Process of Text Annotation
Performing NLP through text annotation itself is a detailed process and it includes sub-processes. Following a set fixed process works wonders when it comes to text annotation. In the following ways or stages, text annotation is performed for machine learning models.
Stage 1: Data Collection
Text data is a vital element in this annotation process. So, the first step is to collect raw text data from different resources. By aiming for your project objectives, you need to collect relevant text data from different sources.
Stage 2: Data Cleansing and Enrichment
After collecting data, you need to prepare the data from the annotation work. Data cleansing is the intermediate process that helps remove bad elements from your data and make it easily deployable. Through data cleanliness operations, irrelevant content from text data gets removed, and it presents the text format in a structured manner.
Stage 3: Setting Annotation Guidelines
Drafting clear guidelines always helps to annotate text data better. Following a strict guideline will make the annotation tasks consistent and accurate over time. Set guidelines for project timeline, procedure, and completion altogether along with quality improvement matters. Uniformity of the annotation work must be maintained throughout the project and setting guidelines help in that.
Stage 4: Deciding Tasks and Team Creation
Text annotation is a special subject and it needs trained staff members to perform. Here you have to recruit people who are experts in text annotation or else you can outsource text annotation services to get the work done via an expert team. Only comprehensive training can increase the accuracy level of text annotation.
Stage 5: Annotation Workflow
Channeling each task in step-by-step order helps smooth the annotation workflow. To maintain the flow, you need to set tools, define the quality of work, redesign strategic workflow based on the situation, and do more things. Keep a feedback loop in the process to improve the system in real time.
Stage 6: Quality Enrichment
Maintaining a quality standard is always important as it checks the quality in control. To enhance the text labeling standards, you need to include feedback sessions during the process. Further, besides enriching the quality, you must implement measures to increase the confidentiality of data is also important.
Why Companies Should Do Text Annotation
From the healthcare system to the banking sector, the development of NLP and its good uses are rampant. At present, the development of language-based AI is at its peak. In various spheres, AI technology is doing wonders.
Besides that, there are many ways text annotation helps across industries. In the coming years, more new developments will enrich this process. Therefore, it’s the right time for you to adopt or develop a language-based AI system at your work. AskDataEntry is there for your help regarding any type of text annotation work. You can connect with us to get accurately annotated text data as per your requirements.