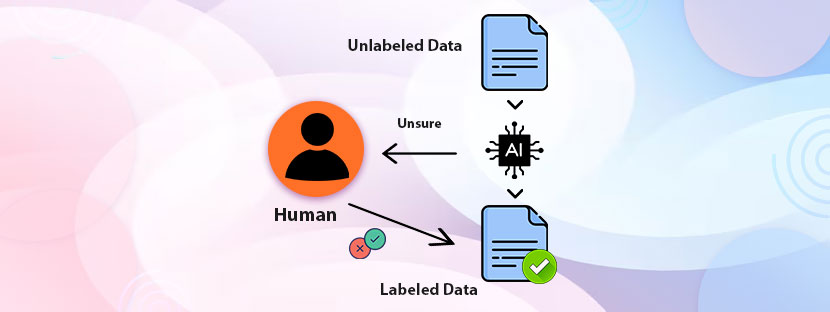
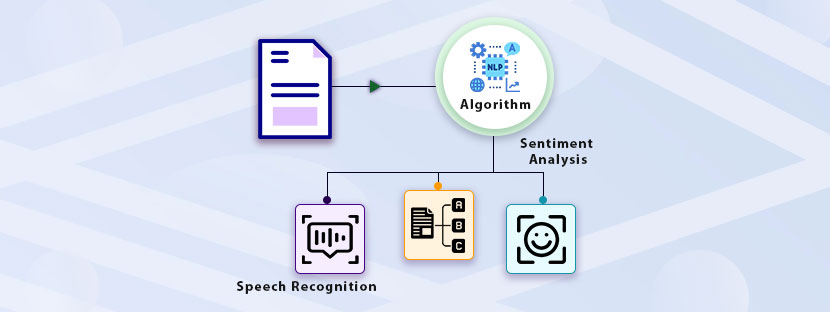
Classification in machine learning is a process in which ML models predict correct labels for input data with the help of a classification algorithm.
Machine Learning (ML) models predict things with the help of different algorithms. You need to prepare data for classification machine learning development algorithm. This special category of algorithm simplifies the data prediction process. It classifies data into different categories to help the ML models accurately predict data.
Let’s talk more about data classification in this blog. We will cover here all the core concepts of ML data classification, along with various types of classification.
Shall we begin?
A Brief about Supervised Learning
Before starting with the classification algorithm, you need to have a coherent knowledge of supervised learning.
Let’s understand how supervised learning works with an example. Suppose you are trying to learn maps to enhance your geographical knowledge. At first, you may be trying to remember locations by constantly checking them. Once you gain confidence in your ability to remember place locations without checking the map again and again, you may stop checking your maps frequently. Now you can easily remember the exact locations of the places when you hear their names.

Supervised learning works in a similar fashion, where ML models learn from examples. It’s a continuous process where ML models keep learning from new experiences. Supervised learning provides data with input variables and assigns correct labels to them. Thereafter, the algorithm analyzes the relationships between the input variables and assigns labels to understand how each data point is related to another. Gradually, it develops the predictive labels of new and unseen data.
With the integration of supervised models, ML algorithms can perform;
- Detect spam emails and also train ML models on what a spam mail is and what is not a spam mail.
- Recognize voices and train ML models for speech recognition
- Detect objects and train ML models on what an object looks like and describe its characteristics.
Classification is a sub-category of supervised learning. Let’s talk about it in the next section.
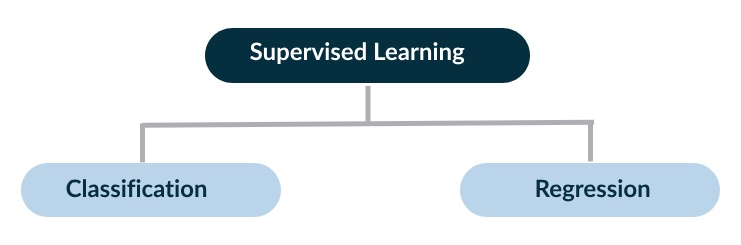
What is Data for Classification Machine Learning
Classification is a process of creating groups for similar-looking objects or data, or even ideas. It involves creating categories of data points based on their characteristics and features. The ultimate goal of data classification is to develop an ML algorithm that accurately categorizes labels for unseen data based on the learning it got from the training datasets.
Data for classification machine learning is a part of the broad supervised learning. Just like supervised learning, classification widely helps in spam detection, object recognition, sentiment analysis, speech recognition, and other applications.
Interestingly, there’s no sharp difference between classification and pattern recognition. Classification is more like detecting patterns in the data points.
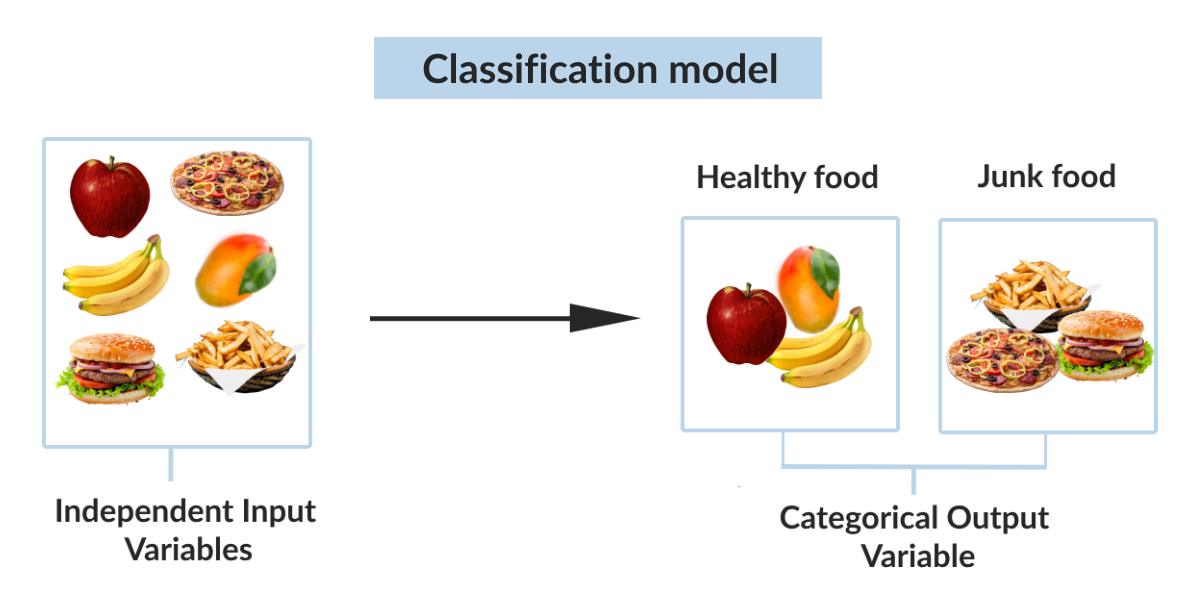
It’s more like classifying and labeling objects, like pattern recognition. For example, in software applications that detect sentiments, data classifications help identify and label sentiments. Based on the available sentiments and tones, the algorithm will classify data into positive, negative, neutral, and other categories.
Learners in Classification Problems
Machine learning algorithms can be classified broadly into two groups, which are
- Lazy Learners
- Eager Learners
Lazy Learners
Lazy learners are also known as instance-based learners. They do not learn learn from the training; instead, they store training data in memory. When it comes to identifying new data, it immediately compares the new data with the stored instances. Ultimately, they predict most similar instances and label the data accordingly.
Commonly observed data for classification machine learning through lazy learners are KNN (k-nearest neighbors) and the case-based reasoning algorithm.
Eager Learners
On the flip side of lazy learners, eager learners put more computational resources into the training phase. It builds a specific algorithm during the training phase in itself. This model puts all learned knowledge during training to predict new instances. This model directly predicts unseen data faster. That’s the reason why a large number of companies trust eager learners to develop their ML models.
Classification Vs Clustering in ML
To better understand data for classification machine learning, we have to compare classification with clustering. Both concepts sound similar, but have huge differences. Let’s explore them one after another.
A classification algorithm works to predict and label unseen data instances. It has a direct relationship with supervised learning. Plus, it only deals with labeled data and nothing else.
On the other hand, a clustering algorithm deals with unlabeled data. However, clustering is basically an unsupervised learning technique. It puts data into similar groups based on similar patterns. It does not consider predefined labels or classes to predict data.
Most likely, the choice of selecting classification over clustering or vice-versa depends on the nature of the data our ML model needs, along with the outcome you are expecting.
Types of data for classification machine learning algorithm
Machine learning algorithms classify data into these four types;
- Binary Classification
- Multi-Class Classification
- Imbalanced Classification
- Multi-Label Classification
Let’s now have a look at each of the types in detail.
Binary Classification
Like the word binary, this classification task can only classify instances into two outcomes or classes.
For example, it predicts sales conversion instances as buy or not, detects spam emails as spam or not, etc.
Basically, this model is suitable where only two classes are there. With the help of data annotation for machine learning, binary classification can be done perfectly.
Multi-Class Classification
Multi-class labels are deployed to classify tasks, which come in a group. This model of data for classification machine learning algorithm puts instances into class groups, instead of giving them separate class labels. Algorithms such as progressive boosting, choice trees, rough forest, etc., directly use multi-class classification models.
Imbalanced Classification
When the datasets belong to an abnormal class, then they get identified and labeled via the imbalanced classification methods. Mostly, this technique is widely popular for identifying anomalies.
Multi-Label Classification
Think of a photo that captured multiple objects like persons, bicycles, cars, signal posts, and other things. To classify each object, you need to apply multi-label classification procedures. It would apply separate labels to separate objects and classify them.