In This Article
Raw data mainly misses out on three things;
➭ Intact formatting
➭ Integrated setting
➭ Updated valid information
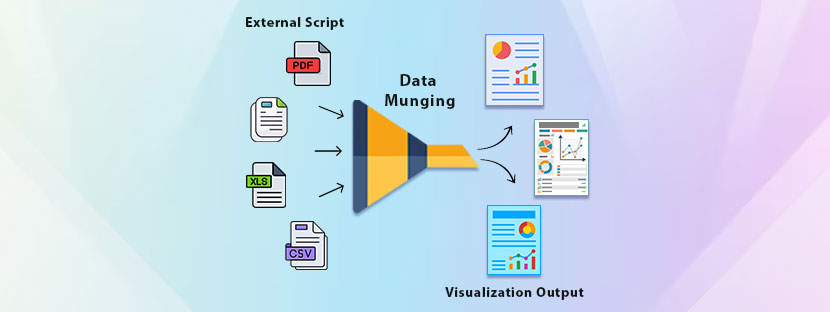
Analytics cannot fix raw data. Thus, it requires an additional step to fix the data before it reaches analytics. That step is data munging. This step involves a series of processes that convert raw data into a usable format.
Let’s not see how it happens;
Filling up data gaps
Data gaps get created due to missing datasets. Missing data can happen due to various reasons. Errors while collecting data, system failure, or simply because of the non-applicability of data are the common reasons why incidents of data missing happen. The solution to rectify the issue of missing data depends on the degree of missingness.
Treat missing data separately. Better if you could create a category to treat missing data. Having a proper category for missing data requires you to register missing data.
Leave all your missing data for machine learning algorithms. Some of the applications, like decision trees or random forests, etc, work better to fill up missing values in intact format.
With proper information, missing data can have binary flags in it. You can easily identify which fields have no data.
Combining datasets
Combining datasets together and creating a consolidated database out of them is important. But you need to integrate data from various sources into a unified framework. It helps you to facilitate more accurate analysis and insight extraction.
All the dataset combination activity starts using a series of activities. It includes merging, aggregating, joining, and reshaping data to form a coherent dataset, which is integrated within your data sources. Integrating datasets can be simple. It requires you to follow up on some simple techniques, which are
🎯 Combine datasets that are the same in nature or have the same structure. This process is also known as data concatenation. Before you initiate this process, you need to append your data using valid resources.
Combine your datasets in the typical SQL style. It will join all your datasets based on a shared key. This technique is most common and widely used in combining structured data that has standard identifiers. For example, product ID, customer ID, etc.
Applying a data aggregator can help up to a certain extent. To apply it, you need to combine all your data based on the group or category and then perform the summary statistics.
Cleansing up the existing database
Mistakes can happen, especially when it comes to data practices. The most common mistakes found in the data processes are data inconsistencies, poor records, and unverified datasets. All these mistakes add up to cause bad data. Putting bad data can create an imbalance in the data channels. Therefore, it requires a proper data cleansing mechanism to eradicate poor records from scratch.
⟢ The first method you have is imputation. It is suitable for numerical columns. It fills up missing values with the mean for generally distributed data to assess skewed data. Use the median and mode formula if the data appear in categorical columns.
⟢ Next, you have a method named forward fill and backward fill. Forward fills are there to carry the last known value, and backward fill holds the next available value. Using both options, you can fill all the missing data points.

Challenges you may face when munging data
Data munging looks quite simple from the outside, but it is difficult when you implement it in real-time. Many organizations face difficulties when they introduce data munging into regular practices. On a special mention, it becomes quite problematic when machine learning gets the data via data munging.
We have highlighted some of the major challenges as well as some ignorable challenges in this section. All these are either related to data munging applications or implementation.

Complexity in data integration
If data structures are available in a complex format, it creates a roadblock in integration. For example, there are multiple sets of data, but they are available in multiple formats, i.e., JSON, XML, Excel, and some in plain text. When combining them, you can create nothing but a mess.
It’s hard to combine complex data because of the following three reasons;
🪢 You cannot mess with the nested structure for the sake of conversion
🪢 Data processing requires further breakdown and correction tests
🪢 Special techniques are required if the data is related to images, audio, and videos
All these processes can get a straight line if the complexities in data integration are reduced. All your data should stay aligned closely. Key matching can do many things for you.
☯ On the other hand, schema differences, i.e., differences in names or structures, may require adjustments. Complexity in combining data makes things critical for us to handle and process.
Data quality management
Quality data is an absolute need for analytics. Including high-quality data in analytics improves the accuracy and reliability of the insights (i.e., the outcomes). However, for your reference, managing the quality issues is one of the most challenging tasks in this process.
Let’s check here how you can skip data quality issues from your database and bring fresh data forward.
Tackle missing data using data enrichment tactics. Missing fields distort data analysis. Results can get skewed if you keep allowing missing datasets into the processing parts. Enrichment can fix missing values. It provides additional and relevant values to the missing fields. Besides enrichment, you need to understand the key reasons behind it.

Don’t worry! Applying the data enrichment tactics can fix things up. Mistakes can happen at any point in time, but fixing them quickly is the best way to deal with them.
Standardize all your datasets to remove inconsistencies. Similar ranges of data can appear multiple times within a database. Due to their inconsistent nature, they should be removed from your database. Some common types of inconsistent errors are different naming conventions, data available in various formats, etc.
Follow the data deduplication rules diligently across all the fields. One set of data must not repeat anywhere in your database. Otherwise, the flow will be distorted. Make sure you put only unique values to all your datasets.